
In cutting-edge statistics-driven world, the sphere of information technology stands as an impressive pillar, orchestrating the symphony of records and expertise. Data science jobs is more than just a buzzword; it’s a effective field that unearths hidden insights from enormous amounts of facts, imparting extraordinary opportunities to apprehend and effect our world.
From predicting the weather to recommending your subsequent movie, from optimizing supply chains to unraveling the mysteries of the human genome, information technological know-how has its fingerprints on almost every element of our lives. In this complete manual, we can embark on a journey on data science jobs via the problematic landscape of records technology, exploring its center ideas, methodologies, and programs.
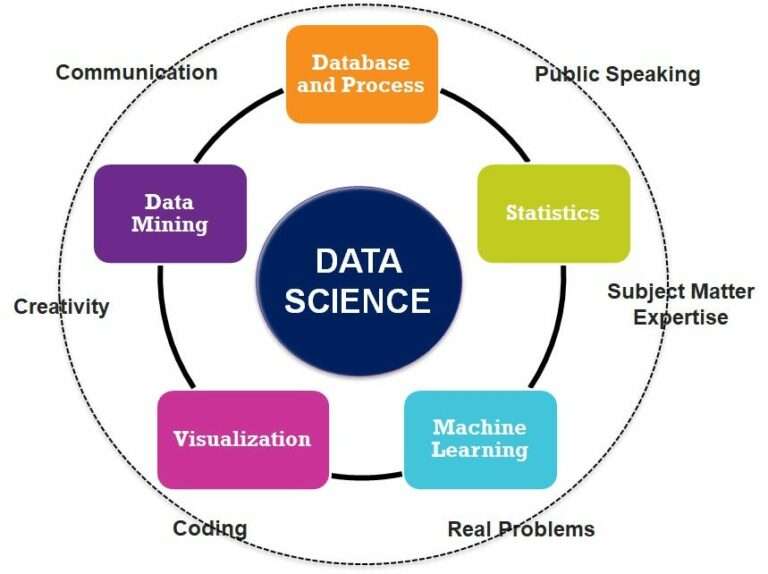
Data Collection and Preparation
1. Data Collection Methods
data science jobs strategies range primarily based on the supply and form of statistics.
Some common methods consist of data science jobs:
- Batch Processing: Collecting statistics in large batches periodically.
- Real-time Data Streaming: Continuously amassing records as it’s generated.
- Surveys and Questionnaires: Gathering records thru designed surveys.
- Web Scraping: Extracting records from websites the usage of web scraping tools and libraries.
- API Integration: Accessing records through APIs provided by means of diverse on-line offerings.
- Data Entry: Manually inputting records whilst computerized strategies aren’t possible.
2. Data Cleaning and Preprocessing
- Once records is accrued, it’s critical to smooth and preprocess it to ensure its quality and suitability for analysis. This entails several tasks:
- Handling Missing Data: Dealing with missing values, which may also involve imputation or elimination.
- Dealing with Outliers: Identifying and coping with records factors significantly distinct from the relaxation.
- Data Transformation: Scaling, encoding express variables, and function engineering.
- Data Normalization: Ensuring information follows a regular scale or distribution.
- Duplications and Noise Removal: Eliminating duplicates and decreasing random variations.
- Data Validation: Checking for data consistency, integrity, and adherence to predefined requirements.
Exploratory Data Analysis (EDA)
data science jobs
1. Understanding EDA
Exploratory Data Analysis is the system of visually and statistically summarizing, studying, and interpreting statistics. It plays a vital role in understanding the underlying styles, relationships, and anomalies within your dataset.
Here’s why EDA is crucial:
- Data Understanding: EDA helps you get acquainted along with your records, making it easier to become aware of key features, tendencies, and capacity troubles.
- Data Cleaning: EDA frequently famous facts fine problems, inclusive of missing values, outliers, or inconsistencies, which may be addressed at some stage in this segment.
- Hypothesis Generation: EDA allow you to form hypothesis approximately your information, which could guide further analysis and modeling.
- Visualization: EDA uses visualizations to symbolize statistics, making it more handy and allowing the communique of findings to non-technical stakeholders.
2. Data Visualization
- Data visualization is a cornerstone of EDA. It makes use of graphical representations to convey records about the dataset. Some commonplace visualization techniques consist of:
- Histograms: Displaying the distribution of a single variable.
- Box Plots: Showing the spread and skewness of information.
Scatter Plots: Visualizing relationships between two variables. - Bar Charts: Representing express records.
- Heatmaps: Visualizing the correlation between variables.
- Time Series Plots: Displaying facts over the years.
Visualization not only facilitates in figuring out styles however also in revealing outliers and statistics structure.
Data Modeling
data science jobs
1. Introduction to Data Modeling
- Data modeling is the method of making a mathematical representation of a real-international gadget the usage of statistics. It serves two primary functions:
- Predictive Modeling: Building fashions to make predictions about destiny or unseen data points. This is not unusual in scenarios like income forecasting or consumer churn prediction.
- Descriptive Modeling: Creating models to benefit a better knowledge of the relationships inside the statistics. For example, clustering information to locate herbal groupings.
2. Types of Data Models
There are numerous kinds of statistics models, such as:
- Linear Models: Used when the connection among variables is linear. Examples consist of linear regression and logistic regression.
- Decision Trees: Models that cut up records into branches based totally on decision policies.
- Ensemble Models: Combining multiple models to improve predictive accuracy, including random forests and gradient boosting.
- Neural Networks: Deep getting to know fashions inspired by way of the human mind, powerful in obligations like image reputation and herbal language processing.
- Clustering Models: Grouping similar facts points collectively, like okay-approach clustering.
- Dimensionality Reduction Models: Reducing the quantity of variables at the same time as preserving important information, as in Principal Component Analysis (PCA).
3. Selecting the Right Model
Choosing the right model to your information is a critical selection within the records modeling system. Consider the following factors:
- Data Type: The nature of your statistics (e.G., dependent, unstructured) affects the choice of version.
- Model Complexity: Simplicity often performs better than complex models unless justified.
- Interpretability: Some models are less complicated to interpret than others, which is important in packages like healthcare and finance.
- Feature Engineering: The available capabilities can guide your version desire.
- Performance Metrics: The metrics you need to optimize, inclusive of accuracy, precision, don’t forget, or F1 score, will have an effect on the model selection.
Machine Learning in Data Science
- Machine Learning in Data Science jobs.
Machine getting to know is the using pressure in the back of many facts technological know-how applications. In this bankruptcy, we are able to discover the fundamentals of machine getting to know, its various sorts, model evaluation, and hyperparameter tuning.
1. Overview of Machine Learning
Machine learning is a subset of synthetic intelligence that focuses on growing algorithms capable of learning from statistics to make predictions or selections. It is broadly categorised into 3 types:
- Supervised Learning: In supervised getting to know, models study from categorized records, making predictions or classifications primarily based on known effects. Common algorithms include linear regression, choice timber, and support vector machines.
- Unsupervised Learning: Unsupervised gaining knowledge of entails uncovering patterns in records without labeled results. Clustering (k-manner, hierarchical clustering) and dimensionality reduction (PCA) are standard unsupervised techniques.
- Semi-Supervised and Reinforcement Learning: Semi-supervised mastering uses a combination of classified and unlabeled statistics, whilst reinforcement studying specializes in mastering thru interaction with an environment, often used in robotics and gaming.
2. Supervised Learning
Supervised mastering is extensively applied in information technological know-how. Key standards consist of:
- Regression: Used to predict a non-stop output, together with house fees or temperature.
- Classification: Applied to categorize information into lessons or labels, like junk mail or no longer spam emails, or disorder analysis.
- Model Evaluation: Metrics including accuracy, precision, don’t forget, F1 rating, and ROC curves are used to assess version performance.
3. Unsupervised Learning
Unsupervised getting to know is ordinarily used for pattern discovery and statistics discount. Common strategies encompass:
- Clustering: Grouping comparable facts points into clusters, as in okay-method clustering.
- Dimensionality Reduction: Reducing the range of variables even as preserving vital information, often through Principal Component Analysis (PCA).
Big Data and Data Science
1. What is Big Data?
Big Data refers to widespread and complex datasets that exceed the capacity of conventional statistics processing systems.
- Volume: Big Data entails big quantities of records which can variety from terabytes to petabytes and past.
- Velocity: Data is generated and amassed at excessive speeds, frequently in actual-time, from various resources like social media, IoT devices, and sensors.
- Variety: Big Data is available in diverse bureaucracy, together with based records (e.G., databases), unstructured data (e.G., textual content, pictures), and semi-established data (e.G., JSON).
2. Challenges of Big Data
Managing and studying Big Data poses precise demanding situations:
- Storage: Storing big datasets efficiently and fee-effectively is a project. Traditional databases might not be enough.
- Processing: Traditional facts processing equipment may be too gradual for analyzing massive datasets. Distributed processing systems like Hadoop and Spark are regularly used.
- Data Quality: Ensuring facts high-quality and consistency is hard when handling numerous resources and formats.
- Security and Privacy: Protecting touchy statistics turns into extra essential as the quantity and style of facts boom.
3. Big Data Tools and Technologies
Several tools and technology are designed to handle Big Data efficiently:
- Hadoop: An open-source framework for dispensed storage and processing of large datasets.
- Apache Spark: A speedy and preferred-reason cluster computing gadget for Big Data processing.
- NoSQL Databases: Designed to handle unstructured and semi-dependent records effectively, consisting of MongoDB and Cassandra.
- Data Warehouses: Specialized databases for storing and querying big datasets, consisting of Amazon Redshift and Google Big Query.
- Data Lakes: Repositories for storing huge volumes of raw facts in its native layout, regularly the use of cloud-primarily based answers like Amazon S3.
- Stream Processing: Tools like Apache Kafka for real-time facts processing.
Data Science in Practice
1. Real-global Data Science Projects.
Data science jobs tasks are implemented across numerous industries, including:
- Healthcare: Analyzing patient facts for sickness prediction, customized medication, and optimizing healthcare operations.
- Finance: Predicting stock fees, chance evaluation, fraud detection, and customer sentiment analysis.
- Retail: Recommender systems for customized shopping stories, stock management, and demand forecasting.
- Marketing: Customer segmentation, marketing campaign optimization, and sentiment evaluation on social media.
- Manufacturing: Predictive maintenance to lessen downtime, great manipulate, and deliver chain optimization.
- Transportation: Traffic analysis, path optimization, and predictive protection for cars.
2. Best Practices in Data Science Jobs.
To make sure the achievement of facts science initiatives, numerous high-quality practices need to be accompanied:
- Problem Definition: Clearly outline the trouble you are attempting to solve and set up measurable objectives.
- Data Collection: Collect first-rate, relevant facts that aligns with the trouble statement.
- Feature Engineering: Carefully choose and engineer relevant features to improve version overall performance.
- Model Selection: Choose suitable algorithms and fashions primarily based at the trouble kind.
- Evaluation Metrics: Select suitable evaluation metrics to measure the success of your models.
- Model Deployment: Deploy fashions in a production surroundings and constantly display their overall performance.
- Interpretability: Aim for models that can be explained and interpreted, mainly in domains with regulatory requirements.
Frequently Asked Questions (FAQs)
Information science may be a multidisciplinary field that employments logical strategies, calculations, forms, and frameworks to extricate experiences and information from organized and unstructured information.
Information researchers regularly require abilities in programming (e.g., Python), factual investigation, information control, machine learning, information visualization, space information, and solid communication aptitudes.
Data analysis may be a component of data science. Data analysis includes inspecting, cleaning, and transforming data to find experiences and designs.
Machine learning is a subset of records science. Data technological know-how makes use of machine getting to know strategies to build predictive fashions and make data-driven choices. Machine mastering is the technique of schooling algorithms to examine from facts and make predictions or take moves with out being explicitly programmed.
Popular equipment for information technology consist of programming languages like Python and R, Jupyter notebooks for interactive statistics evaluation, libraries like scikit-study and TensorFlow for system mastering, records visualization equipment like Tableau and Matplotlib, and statistics processing structures like Apache Spark.







